Kubernetes 노드 메모리 리밸런싱 — OOMKilled 해결과 워크로드 분산
Control Plane 노드에 메모리 대식가 워크로드가 몰려 OOMKilled가 반복됐다. fork()와 Copy-on-Write 메커니즘을 이해하고 affinity/toleration으로 워크로드를 분산한 과정.
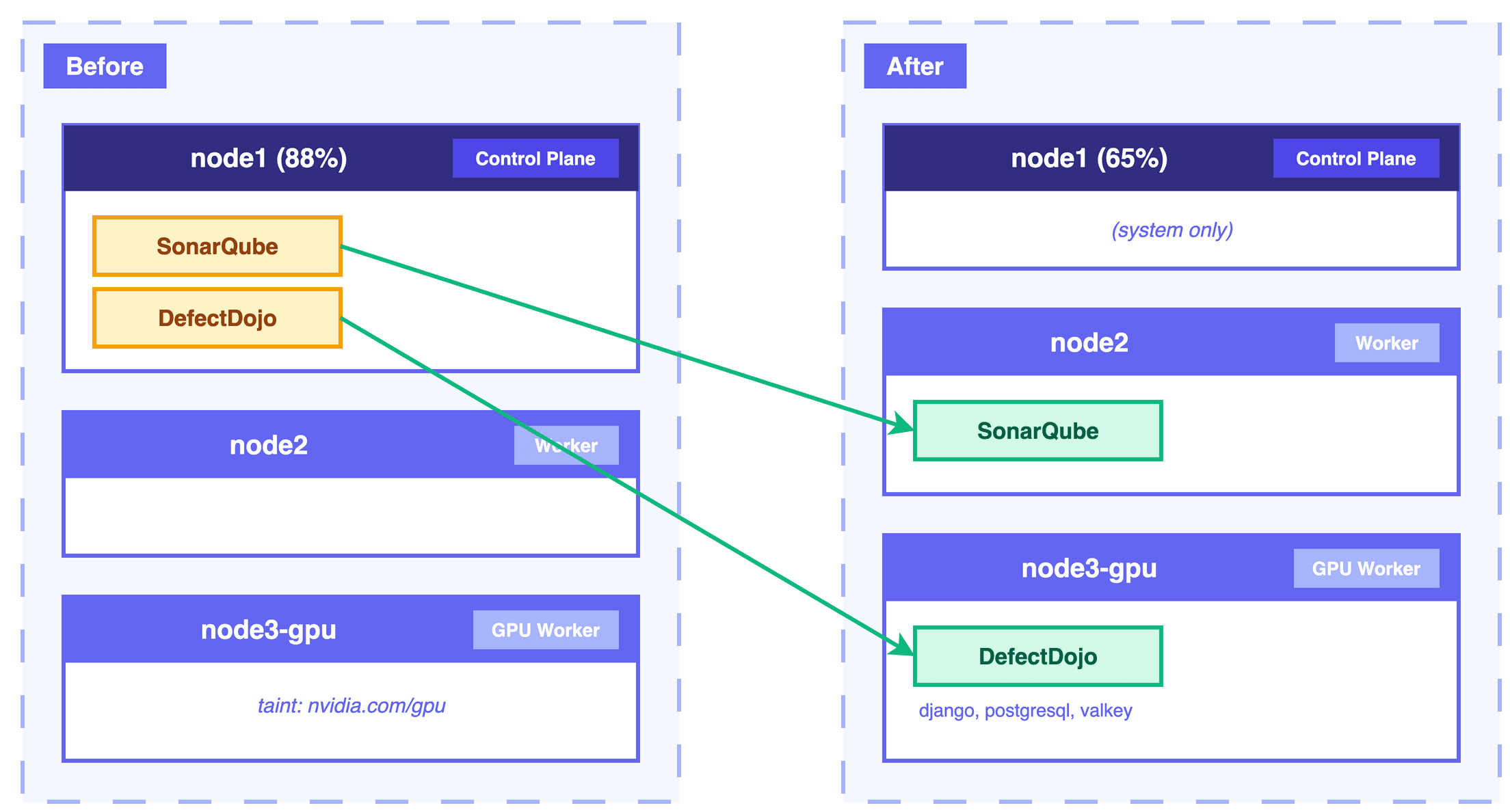
node1에 메모리 대식가 워크로드가 몰려 88% 사용률에 도달했고, DefectDojo의 valkey가 OOMKilled로 2091회 재시작을 반복했다. 근본 원인을 분석하고 affinity/toleration을 활용해 워크로드를 분산한 과정을 정리한다.
환경
- Kubernetes 1.32 (kubespray), Cilium Gateway API
- 노드 3대: node1 (Control Plane + Worker), node2 (Worker), node3-gpu (GPU Worker)
- Longhorn 분산 스토리지
- DefectDojo (보안 취약점 관리): django, postgresql, valkey, celery
- SonarQube (코드 품질 분석)
문제 상황
node1 메모리 과부하
kubectl top nodes 결과 node1 메모리 사용률이 88%에 도달했다. 주요 원인:
| 워크로드 | 메모리 사용량 | 노드 |
|---|---|---|
| SonarQube | ~2.1GB | node1 |
| DefectDojo (django + postgresql + valkey) | ~1.5GB | node1 |
valkey OOMKilled 반복
DefectDojo의 valkey(Redis 호환 캐시) pod가 OOMKilled 상태로 2091회 재시작을 반복했다.
defectdojo-valkey-master-0 0/1 OOMKilled 2091 7d설정값:
- requests: 64Mi
- limits: 64Mi (chart 기본값이 override)
- 실제 RDB 로드 시 사용량: 57.91MB
64Mi 한도에서 57.91MB를 사용하고 있었는데 왜 OOM이 발생했을까?
근본 원인 분석
valkey OOMKilled: fork()와 Copy-on-Write
valkey/Redis는 데이터를 메모리에 저장한다. 서버 재시작 시 데이터 유실을 방지하기 위해 주기적으로 RDB 스냅샷을 디스크에 저장한다.
저장 방식 비교:
| 방식 | 동작 | 단점 |
|---|---|---|
| 동기식 | 메인 프로세스가 직접 저장 | 저장 중 서비스 멈춤 |
| 비동기식 (fork) | 자식 프로세스가 저장 | 메모리 추가 필요 |
valkey는 서비스 중단 없이 저장하기 위해 fork() 를 사용한다.
fork() 동작 흐름
1. 부모 프로세스: "지금 메모리 상태를 저장해야겠다"2. fork() 호출 → 자식 프로세스 생성 (메모리 공유)3. 자식: 메모리 내용을 디스크에 쓰기 시작4. 부모: 클라이언트 요청 계속 처리5. 자식: 저장 완료 후 종료Copy-on-Write 메커니즘
fork() 직후에는 메모리를 복제하지 않는다. 부모와 자식이 같은 메모리 페이지를 공유한다.
fork() 직후:부모 프로세스 ─┬─ 메모리 페이지 A (공유)자식 프로세스 ─┘복제는 쓰기가 발생할 때 일어난다 (Copy-on-Write):
부모가 데이터를 쓰면:부모 프로세스 ── 메모리 페이지 A' (새로 복제)자식 프로세스 ── 메모리 페이지 A (원본 유지)OOM 발생 시나리오
valkey가 57MB를 사용하던 상황에서:
- background save 시작 → fork() 호출
- 자식 프로세스가 RDB 저장 중
- 부모 프로세스는 클라이언트 요청 처리 → 데이터 쓰기 발생
- 쓰기가 발생한 페이지마다 복제 → 메모리 급증
- 최악의 경우 2배 메모리 필요 (57MB × 2 = 114MB)
- 64Mi 한도 초과 → OOMKilled
스케줄링 불균형: requests 기반 배치
Kubernetes 스케줄러는 Pod를 노드에 배치할 때 requests를 기준으로 판단한다. 실제 메모리 사용량이 아니다.
예시:
- Pod A: requests 100Mi, limits 500Mi, 실제 사용량 400Mi
- 노드 여유 메모리: 200Mi
스케줄러 판단:
- requests(100Mi) 기준 → “여유 있네” → 배치 허용
- 실제 사용량(400Mi) 기준이었다면 → 배치 거부
SonarQube와 DefectDojo 모두 requests가 낮게 설정되어 있었다. 스케줄러는 “별로 안 쓰겠네”라고 판단하고 둘 다 node1에 배치했지만, 실제로는 메모리 대식가들이었다.
node3-gpu taint 문제
requests를 높이면 스케줄러가 분산하겠지만, node3-gpu에는 nvidia.com/gpu taint가 걸려 있다.
taints: - key: nvidia.com/gpu effect: NoSchedule일반 Pod는 이 노드를 피한다. DefectDojo를 node3-gpu에 배치하려면:
- toleration: taint를 무시하고 스케줄링 허용
- affinity: 특정 노드로 강제 배치
해결
Phase 0: valkey 메모리 한도 상향
defectdojo.yaml에서 valkey 메모리 한도를 상향했다.
valkey: master: resources: requests: memory: 128Mi limits: memory: 256Mi64Mi → 256Mi로 변경하여 fork() 시에도 OOM 없이 동작하도록 여유를 확보했다.
Phase 1: SonarQube → node2 이동
sonarqube.yaml에 affinity를 추가했다.
affinity: nodeAffinity: requiredDuringSchedulingIgnoredDuringExecution: nodeSelectorTerms: - matchExpressions: - key: kubernetes.io/hostname operator: In values: - node2Phase 2: DefectDojo → node3-gpu 이동
defectdojo.yaml에 django, postgresql, valkey 각각 affinity를 추가했다. celery는 이미 node2에 있어 이동하지 않았다.
django: affinity: nodeAffinity: requiredDuringSchedulingIgnoredDuringExecution: nodeSelectorTerms: - matchExpressions: - key: kubernetes.io/hostname operator: In values: - node3-gpu
tolerations: - key: nvidia.com/gpu operator: Exists effect: NoSchedule
postgresql: primary: affinity: nodeAffinity: requiredDuringSchedulingIgnoredDuringExecution: nodeSelectorTerms: - matchExpressions: - key: kubernetes.io/hostname operator: In values: - node3-gpu
tolerations: - key: nvidia.com/gpu operator: Exists effect: NoSchedule
valkey: master: affinity: nodeAffinity: requiredDuringSchedulingIgnoredDuringExecution: nodeSelectorTerms: - matchExpressions: - key: kubernetes.io/hostname operator: In values: - node3-gpu
tolerations: - key: nvidia.com/gpu operator: Exists effect: NoSchedule에러 요약
| Phase | 에러 | 원인 | 해결 |
|---|---|---|---|
| 2 | PostgreSQL 인증 실패 | createPostgresqlSecret: true가 helm upgrade 시 새 비밀번호 생성 → 기존 PVC의 DB와 불일치 | Secret을 원래 비밀번호로 수동 패치 |
검증 결과
리밸런싱 후 노드 메모리 분포:
- node1: 88% → 65% (목표 75% 미만 달성)
- node2: SonarQube 정상 동작
- node3-gpu: DefectDojo 정상 동작
- valkey: OOMKilled 없이 안정 동작
핵심 개념 정리
OOMKilled
컨테이너가 메모리 limits를 초과하면 커널이 프로세스를 강제 종료한다. Kubernetes는 이를 OOMKilled로 기록하고 pod를 재시작한다.
fork()와 Copy-on-Write
- fork(): 프로세스를 복제하여 자식 프로세스를 생성. 서비스 중단 없이 백그라운드 작업 수행에 사용.
- Copy-on-Write: fork() 시 메모리를 즉시 복제하지 않고 쓰기 발생 시에만 복제. 평소에는 메모리 효율적이나, 쓰기가 많으면 메모리 급증.
requests vs limits
| 항목 | 용도 | 스케줄러 참조 |
|---|---|---|
| requests | 최소 보장 리소스 | O (배치 기준) |
| limits | 최대 허용 리소스 | X |
스케줄러는 requests만 보고 배치를 결정한다. requests가 낮으면 실제 사용량과 관계없이 한 노드에 몰릴 수 있다.
affinity vs toleration
| 항목 | 역할 |
|---|---|
| affinity | ”이 노드로 가라” (배치 지정) |
| toleration | ”이 taint를 무시해라” (배치 허용) |
taint가 있는 노드에 특정 워크로드를 배치하려면 둘 다 필요하다.
핵심 결정 사항
| 결정 | 근거 |
|---|---|
| valkey limits 256Mi | fork() 시 최대 2배 메모리 필요, 57MB × 2 + 여유 |
| affinity로 노드 지정 | requests 조정만으로는 node3-gpu taint 회피 불가 |
| celery는 node2 유지 | 이미 분산되어 있어 이동 불필요 |
관련 콘텐츠
Gateway API, Ingress를 대체하는 Kubernetes 표준
SIG-Network이 4년에 걸쳐 만든 Gateway API의 핵심 리소스 3가지와 그 관계를 이해하고, Ingress와 무엇이 달라졌는지 정리한다.
KubernetesNGINX Ingress EOL 대응: OCI에서 Envoy Gateway로 마이그레이션
NGINX Ingress Controller 지원 종료에 대비해 OCI Always Free 클러스터에서 Envoy Gateway로 마이그레이션한 경험을 공유합니다.
KubernetesGateway API 전환기 (1) - Cilium을 Kubespray에서 Helm으로
Kubespray로 설치한 Cilium을 Helm 관리로 전환하는 과정에서 겪은 트러블슈팅과 교훈을 공유합니다.