LinkedIn에서 발견한 Tencent WeKnora, GraphRAG PoC하고 PR까지 Merged
LinkedIn에서 발견한 Tencent WeKnora를 홈 Kubernetes 클러스터에서 PoC하고, Helm Chart PR까지 Merge한 여정
LinkedIn에서 누군가 소개해준 Tencent의 WeKnora를 보고 흥미가 생겼습니다. 이전에 일일 기록 자동화 시스템을 만들어서 데이터는 쌓이고 있는데, 이걸 LLM이 더 잘 활용할 수 있게 구조화하고 싶었거든요. 홈 클러스터에서 PoC를 진행하고, 만든 김에 Helm Chart PR까지 기여하게 된 여정을 공유합니다.
WeKnora란?
WeKnora는 Tencent에서 개발한 RAG(Retrieval-Augmented Generation) 플랫폼입니다.
주요 특징:
- 문서 파싱 + 벡터 검색 + LLM 통합
- Agent 모드, MCP 도구 연동, 웹 검색 지원
- GraphRAG: Neo4j 기반 Knowledge Graph 지원
- Go/Gin 백엔드 + Vue.js 프론트엔드
특히 GraphRAG 기능이 눈에 띄었습니다. 단순 벡터 검색을 넘어 엔티티 간 관계를 추출하여 Knowledge Graph로 구축하고, 이를 RAG에 활용하는 방식입니다.
PoC 아키텍처
flowchart LR subgraph cluster[Kubernetes Cluster] ingress[Ingress NGINX]
subgraph weknora[WeKnora Stack] frontend[Frontend] app[App] docreader[DocReader] postgres[(PostgreSQL<br/>pgvector)] redis[(Redis)] neo4j[(Neo4j<br/>GraphRAG)] end
subgraph gpu[node3-gpu] ollama[Ollama<br/>qwen2.5:14b<br/>RTX 3060 12GB] end end
user[👤 User] -->|HTTPS| ingress ingress --> frontend --> app app --> docreader app --> postgres app --> redis app --> neo4j app -->|LLM API| ollama홈 클러스터에서 WeKnora를 운영하고, GPU 노드의 Ollama로 Local LLM을 서빙합니다. PoC 단계에서 토큰 비용 없이 매일 테스트할 수 있는 환경입니다.
Helm Chart 기여
문제: docker-compose만 있고 Helm Chart가 없다
WeKnora는 docker-compose로 배포하는 방식만 제공하고 있었습니다. 저는 도구들을 전부 클러스터에 올려서 HTTPS를 붙여 사용하는 걸 선호하기 때문에, Helm Chart를 직접 만들었습니다.
참조한 CNCF 프로젝트:
적용한 베스트 프랙티스:
| 항목 | 구현 |
|---|---|
| SecurityContext | allowPrivilegeEscalation: false, seccompProfile: RuntimeDefault |
| ServiceAccount | 생성 + automountServiceAccountToken: false |
| Secrets | 기본값 없음 (필수 입력), existingSecret 지원 |
| Resources | requests/limits 명시 |
| Probes | liveness/readiness 설정 |
PR #479 Merged
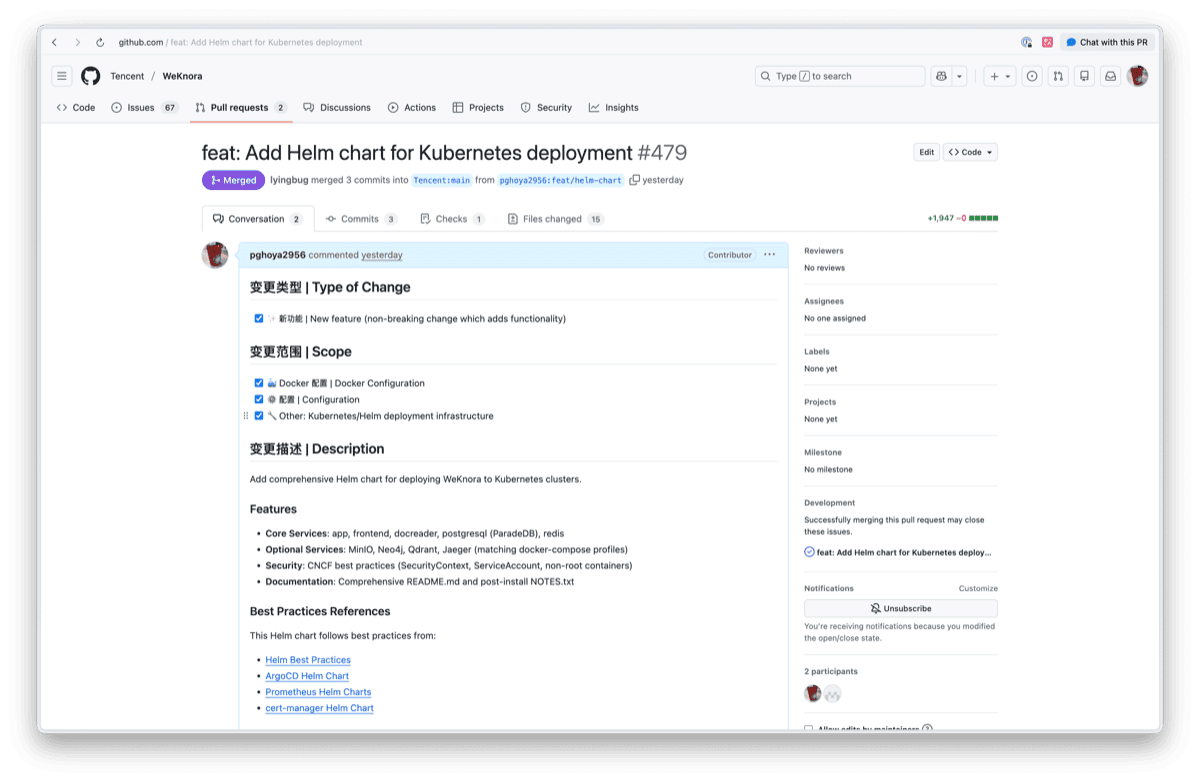
홈 클러스터에서 검증 후 PR을 제출했고, 메인테이너의 리뷰를 거쳐 Merge되었습니다.
PR #479: feat: Add Helm chart for Kubernetes deployment
| 항목 | 내용 |
|---|---|
| Changes | +1,947 additions, 15 files |
| Merged By | @lyingbug (WeKnora 메인테이너) |
| Merged At | 2025-12-24 |
후속 PR: Neo4j 템플릿 추가
GraphRAG 기능을 사용하려면 Neo4j가 필요한데, 첫 번째 PR에서는 누락되어 후속 PR을 올렸습니다.
PR #484: feat(helm): Add Neo4j template for GraphRAG support (Review 중)
Local LLM 구성
왜 Local LLM인가
PoC 단계에서 매일 테스트하다 보면 토큰 비용이 부담됩니다. 마침 홈 클러스터에 GPU 노드가 있어서 Ollama로 Local LLM을 구성했습니다.
[!NOTE] 이번 PoC 중에 GPU 노드에서 Kernel Panic이 발생했습니다. apt 자동 업데이트를 막아두지 않아서 커널이 자동 업그레이드된 게 원인이었어요. GRUB에서 이전 커널로 부팅한 뒤 자동 업그레이드를 비활성화해서 해결했습니다.
Ollama 배포
GPU 노드에 Ollama를 배포하고, Chat Model과 Embedding Model을 로드했습니다.
| 모델 | 용도 | 크기 |
|---|---|---|
| qwen2.5:14b | Chat Model | 8.9GB |
| nomic-embed-text | Embedding Model | 274MB |
RTX 3060 12GB VRAM에서 두 모델이 정상 동작합니다.
GraphRAG PoC
왜 GraphRAG인가
요즘 LLM을 잘 쓰려면 좋은 컨텍스트가 핵심입니다. 아무리 똑똑한 모델이라도 컨텍스트가 부실하면 좋은 답변이 안 나오니까요.
일일 기록을 Notion에 쌓아두고 있는데, Notion 데이터를 LLM 컨텍스트로 활용하려면 매번 가공하는 비용이 듭니다. API로 가져와서 정리하고, 관련 내용을 찾아서 넣어주는 작업이 필요하거든요.
GraphRAG는 문서에서 엔티티(사람, 도구, 프로젝트 등)와 관계를 추출해서 Knowledge Graph로 저장합니다. 이미 구조화되어 있어서 LLM 컨텍스트로 바로 활용하기 좋을 것 같다는 생각이 들었습니다.
WeKnora 배포
작성한 Helm Chart로 WeKnora를 배포했습니다. Neo4j와 Ollama 연동 설정이 핵심입니다.
# weknora values.yamlneo4j: enabled: true password: xxx
app: env: ENABLE_GRAPH_RAG: "true" extraEnv: - name: OLLAMA_BASE_URL value: "http://ollama.ollama.svc.cluster.local:11434"Knowledge Graph 생성
문서를 업로드하고 Entity-Relationship Extraction을 실행하면, Neo4j에 Knowledge Graph가 생성됩니다.
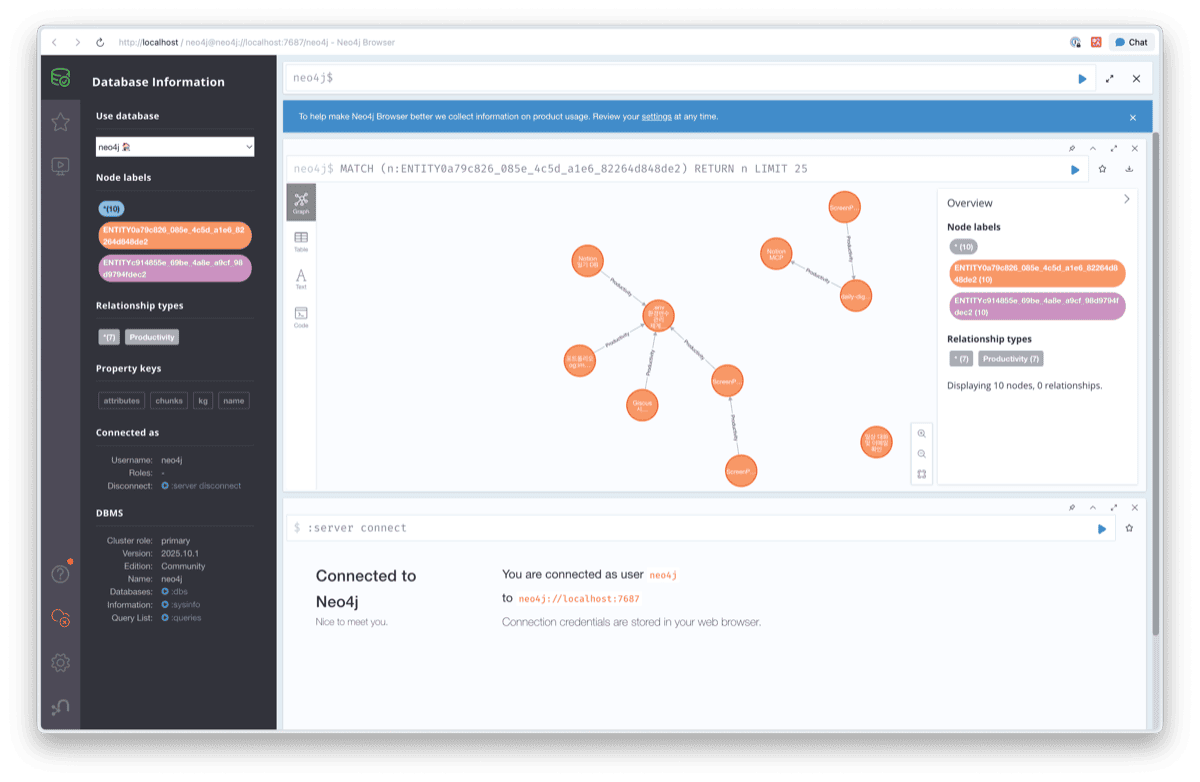
10개의 노드와 7개의 관계가 추출되었습니다. 노드 라벨에는 Productivity, Notion, ScreenPipe 등 문서에서 추출된 엔티티가 표시됩니다.
RAG 응답 테스트
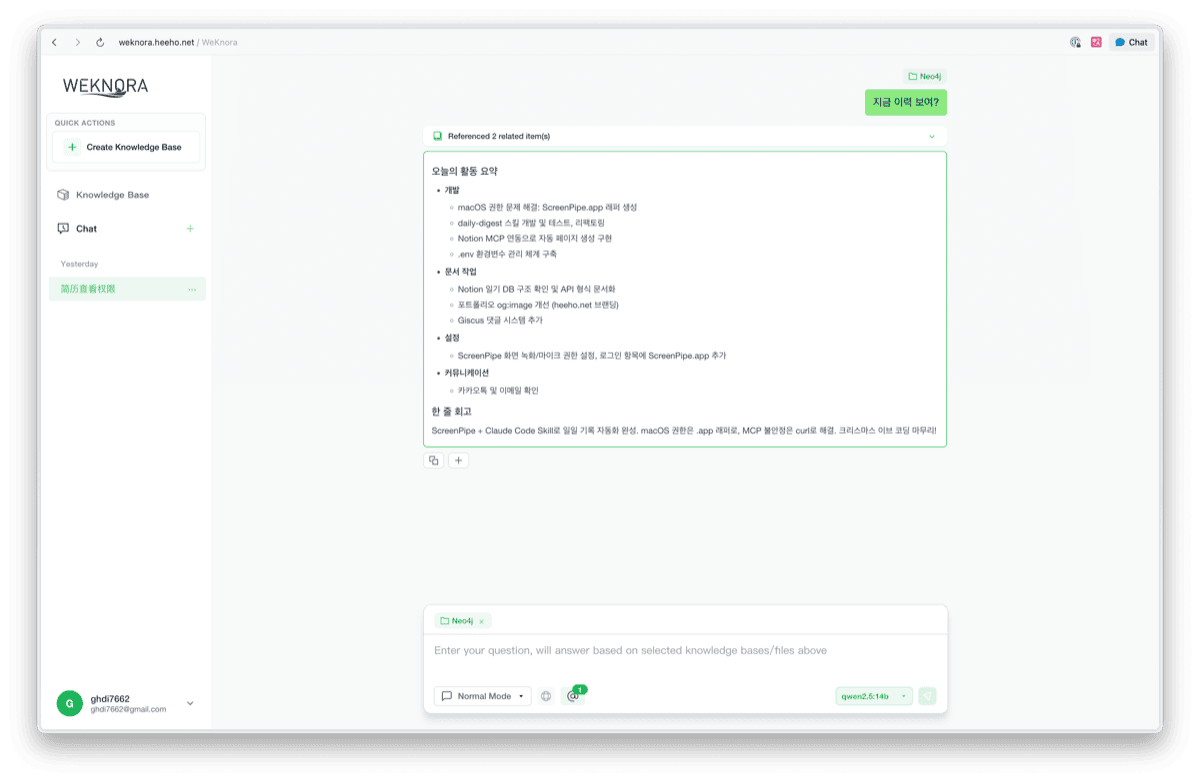
Knowledge Base를 선택하고 질문하면, Vector Search + Knowledge Graph를 활용한 RAG 응답을 받을 수 있습니다. 우측 하단에 qwen2.5:14b 모델이 선택된 것을 확인할 수 있습니다.
LLM 컨텍스트 관점에서 비교
벡터 검색과 GraphRAG의 차이를 LLM 컨텍스트 관점에서 체감했습니다.
| 방식 | LLM에 전달되는 컨텍스트 |
|---|---|
| 벡터 검색 | ”ScreenPipe”가 언급된 문서 조각들 → 단편적 |
| GraphRAG | ScreenPipe 엔티티 + 연결된 Notion, Claude Code, daily-digest 등 → 구조화된 맥락 |
같은 질문이라도 GraphRAG가 제공하는 컨텍스트가 더 풍부합니다. LLM이 “ScreenPipe가 뭐랑 연결되어 있는지”를 이해한 상태에서 답변하니까요.
오픈소스 기여
다음 단계
현재 상태
인프라는 준비됐습니다. Kubernetes에서 WeKnora + Neo4j + Local LLM이 돌아가고, Knowledge Graph 생성까지 확인했습니다. 하지만 GraphRAG를 제대로 활용하려면 아직 배워야 할 게 많습니다.
앞으로 할 것
- GraphRAG 깊이 파기: 엔티티 추출 원리, 관계 정의 방식, 어떤 데이터에 효과적인지 등
- 실제 데이터로 테스트: daily-digest 데이터로 Knowledge Graph 구축해보고 품질 검증
- 자동화 파이프라인: 매일 쌓이는 기록이 자동으로 WeKnora에 업로드되는 구조
- MCP 연동: Claude Code에서 “지난주에 뭐했지?” 같은 질문에 바로 답변
목표
LLM 컨텍스트 인프라: 매일 쌓이는 기록이 자동으로 구조화되고, LLM이 이를 컨텍스트로 활용하는 파이프라인.
이번 PoC를 진행하면서 컨텍스트 엔지니어링을 위한 인프라 자동화에 점점 관심이 생기고 있습니다. LLM 성능은 계속 좋아지고 있으니, 결국 차이를 만드는 건 얼마나 좋은 컨텍스트를 제공하느냐일 테니까요.
참고 링크
- WeKnora: https://github.com/Tencent/WeKnora
- PR #479 (Helm Chart): https://github.com/Tencent/WeKnora/pull/479
- PR #484 (Neo4j): https://github.com/Tencent/WeKnora/pull/484
관련 콘텐츠
n8n v1 → v2 업그레이드: Kubernetes에서 메이저 버전 넘기
n8n v1.120.4에서 v2.9.4로 2단계 순차 업그레이드한 기록. 연쇄 CVE 대응, Migration Report 활용, community node emptyDir 트레이드오프, Queue 모드 호환성 튜닝.
DevOpsEC2 해킹당하고, DevSecOps 파이프라인을 구축하다
사이드 프로젝트 개발 서버가 털린 경험을 계기로 DevSecOps 파이프라인을 구축한 이야기입니다.
DevOps에어갭 환경에서 Helm Chart와 컨테이너 이미지 무결성 검증하기
공격자 관점으로 이해하는 GPG 서명, Cosign 검증, SHA256 해시 비교의 필요성과 실무 적용법